
English Determiners Correction with Tensorflow
Enter sentences like I live in White House, London is a capital of Great Britain or any other sentence you are doubting with and then hit the button.
tl;dr bi-LSTM model for characters and words embedding overtakes the window classification model and reaches 0.764 f1-score on dev set and 0.764 f1-score test set. This system is trained on movie dialogs dataset. Hopefully, with a larger dataset we will be able to achieve better performance. System still fails with sequences like I have a ball. The ball is red.
Table of Contents
Challenge
Given a paragraph, place the determiners (a, an, the) correctly.
Data
We used Cornell Movie Dialogs Corpus. We store each given utterance (no matter how many sentences there are) in a text file with one word and its class per line.
Example: I have a ball. The ball is red.
I O
have O
ball A
. O
ball THE
is O
red O
. O
Train-Dev-Test split
We splitted data to the train, development and test datasets, distributing utterances uniformly by its length. Train-dev-test split can be found in this repo folder
Baseline: Window Classification Model
Determiners are strongly connected with the words around them. Thus, I decided to take a window classification model as a baseline. I took a model from the second assignment of CS224d: Deep Learning for Natural Language Processing, a precursor of CS224n: Natural Language Processing with Deep Learning
A brief overview of window models you can find in CS224n Lecture 4, slide 17.
We used the following configuration:
-
Embed a word and its neightbors using GloVe vectors. We made experiments for window sizes 3, 5 and 7 which corresponds to 1, 2 or 3 neighboor words for a given center word.
-
Apply a one-hidden-layer neural network to classify a given word. We introduce four classes with respect to particular determiners before a given word: O for a blank space, A, AN and THE.
Results
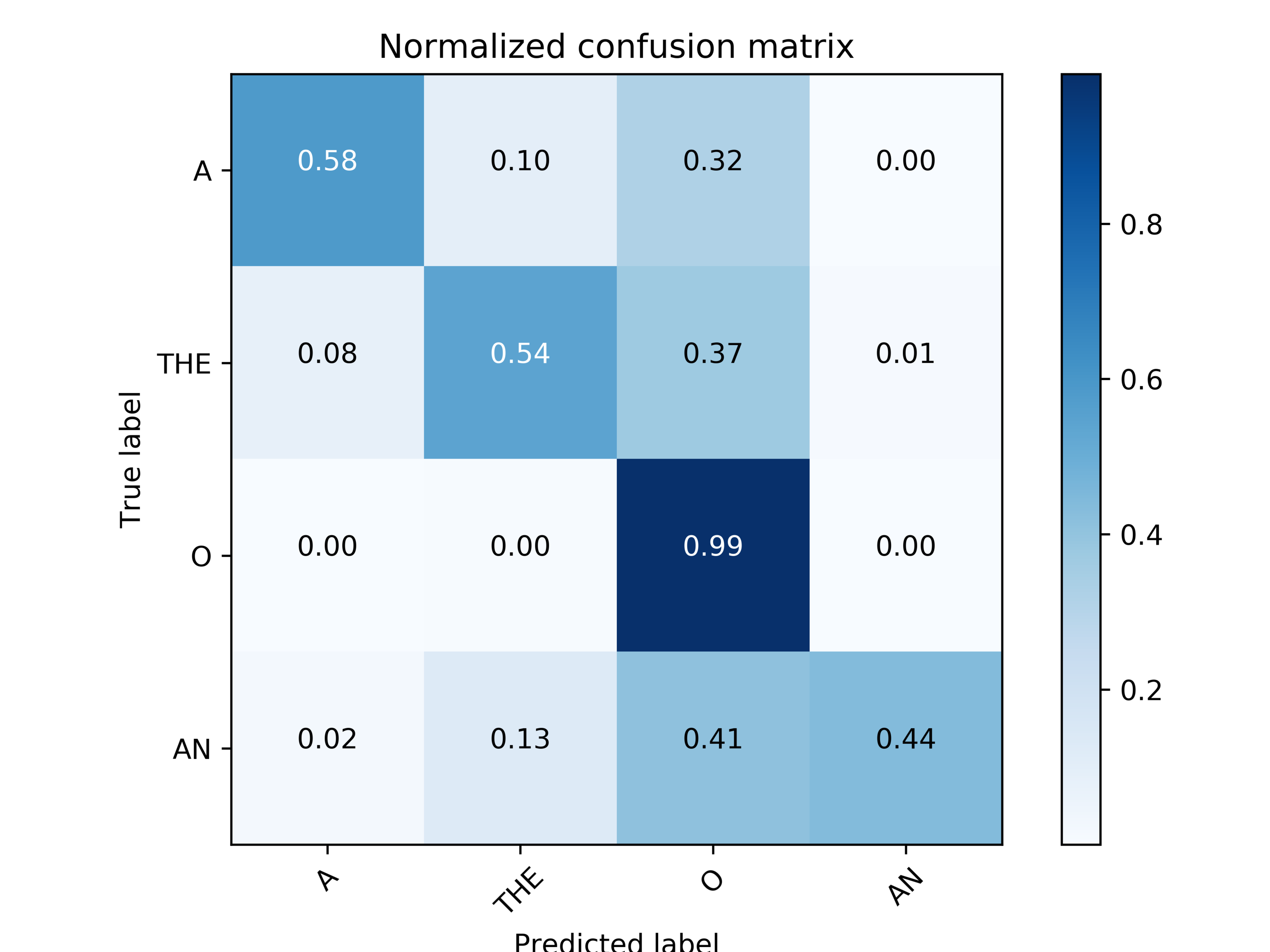
We made 3 experiments with one-hidden-layer fully connected network with different window sizes and obtained the following results:
- Window size 3. F1-score: 0.69
- Window size 5. F1-score: t.b.d.
- Window size 7. F1-score: 0.692
F1-scores are computed on dev tests. Confusion matrix for the model with window size 3 looks as follows:
 |
Final version
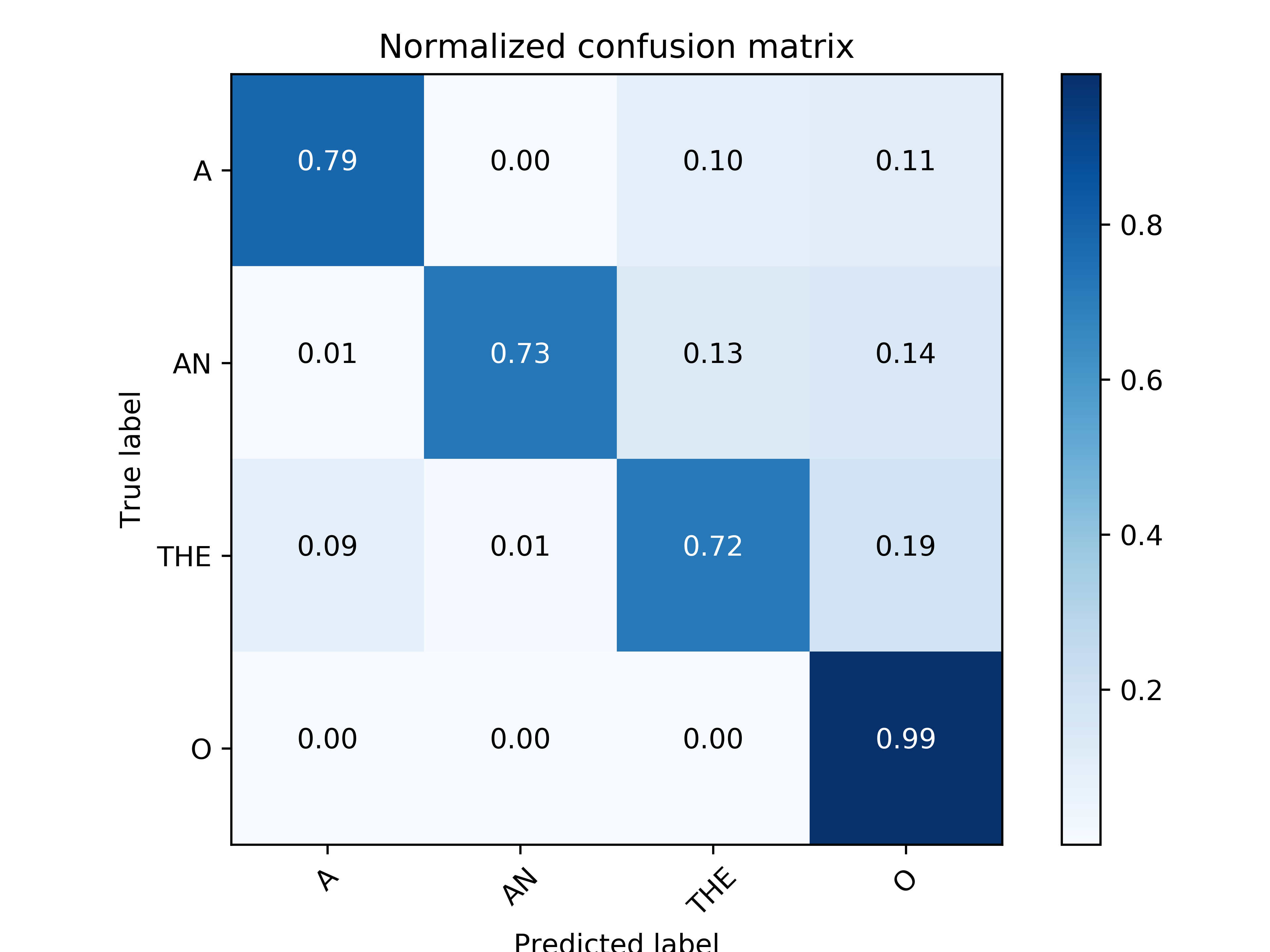
As a more sophisticated model we took a bi-LSTM architecture. We ran the experiments based on Guillaume Genthial’s implementation of bi-LSTM+CRF arhitecture for Named Entity Recognition. Guillaume precisely explains his code in this blogpost.
While CRF was not that helpful in the determiners correction task as on NER, the embeddings for characters and words obtained from bi-LSTM helped to increase f1-score from 69% obtained by window classification model to 75%. However, next steps should be adding attention and an attempt to train this architecture on a larger dataset.
- bi-LSTM+CRF
- DEV f1-score: 76.26
-
TEST f1-score: 76.40
- bi-LSTM+Softmax
- DEV f1-score: 75.08
- TEST f1-score: 74.84
 |